

Identifying causal relationships from observational data is not easy. Still, researchers are often interested in examining the effects of policy changes or other decisions. In those analyses, researchers will face any number of analytical decisions, including whether to use fixed or random effects models to control for variables that don’t change over time.
Let’s consider an example. Suppose we’re interested in estimating the effect that a government grant might have had on firms’ product quality (as examined in this previous study). In addition to controlling for observed variables like the number of employees the firms had at different time points in the study period, we might also want to control for unobserved variables, such as the management quality of the firms.
Assuming that the firms’ management quality is constant over time, we can use regression models to try to account for those unobserved factors — but there isn’t always consensus about the best way to do so. Specifically, researchers often must decide whether to use a fixed or random effects approach in an analysis like this.
In this post, we’ll discuss some of the differences between fixed and random effects models when applied to panel data — that is, data collected over time on the same unit of analysis — and how these models can be implemented in the programming language Python.
Fixed vs. random effects in panel data
Broadly speaking, the distinction between a fixed effects approach and a random effects approach concerns the correlation — or lack thereof — between unobserved variables and observed variables. To highlight this difference, let’s go back to the example cited above.
The key issue in deciding between the two approaches is whether or not the unobserved variables in our analysis — in this case, the firms’ management quality — might be correlated with observed variables. We might use a fixed effects approach if we think that these variables are correlated — for example, if we think firms’ management quality has a role in determining whether the firms receive a grant. But we might use a random effects approach if we think the two variables are not correlated.
Fixed effects help capture the effects of all variables that don’t change over time. In other words, anything else that does not change over time at the firm level, such as its location, would be captured by these fixed effects terms in the model. That means we cannot separately estimate the effect of firms’ location on their performance.
This is quite restrictive for some applications, so researchers who might be interested in studying the effect of time-invariant variables may want to choose the random effects framework instead, even though these models impose stronger assumptions about the unobserved effects.
Using Python to implement the models
Next, we’ll illustrate how to implement panel data analysis in Python, using a built-in dataset on firms’ performance from the `linearmodels` library that follows from the example discussed above. Note that `linearmodels` is only supported in Python 3.
import numpy as np
import pandas as pd
from linearmodels import PanelOLS
from linearmodels import RandomEffectsTo implement a random effects model, we call the RandomEffects method and assign the firm code and year columns as the indexes in the dataframe.
from linearmodels.datasets import jobtraining
data = jobtraining.load()
year = pd.Categorical(data.year)
data = data.set_index([‘fcode’, ‘year’])
data[‘year’] = yearFor the dependent variable, we use the change in scrap rate between periods as a proxy of the product quality. For the independent variables, we include the grant status in period t (=1 if received grant) and the number of employees at the firm.
exog_vars = [‘grant’, ‘employ’]
exog = sm.add_constant(data[exog_vars])
mod = RandomEffects(data.clscrap, exog)
re_res = mod.fit()
print(re_res)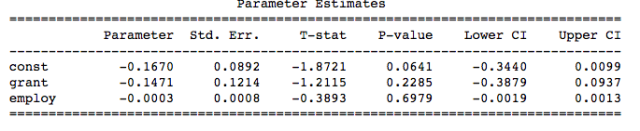
To implement the fixed effects model, we use the PanelOLS method, and set the parameter `entity_effects` to be True.
mod = PanelOLS(data.clscrap, exog)
re_res = mod.fit()
print(re_res)

The results are quite different between the fixed and random effects models, but neither is statistically significant. However, to the extent that you think the unobserved effect of the firms is uncorrelated with whether the firms received the grant, the random effects model is more appropriate.
Equivalence of fixed effects model and dummy variable regression
Estimating a fixed effects model is equivalent to adding a dummy variable for each subject or unit of interest in the standard OLS model. To illustrate equivalence between the two approaches, we can use the OLS method in the statsmodels library, and regress the same dependent variable on the categorized variable of firm, and other independent variables:
data = jobtraining.load()
data[‘year’] = pd.Categorical(data.year)
FE_ols = smf.ols(formula=’clscrap ~ 1 + grant + employ + C(fcode)’, data = data).fit()
print(FE_ols.summary())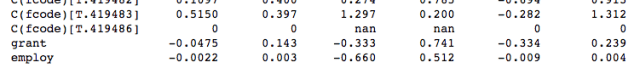
The results from the dummy regression show the separately estimated effect of each firm on change in scrap rate. This is sometimes useful when we want to focus on specific units. In addition, we can compute some sample averages of these estimates to get a sense of how much variation there is across firms.




